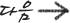기계학습이 있어야 진정한 인공지능이라고 부를 수 있다.
(퀀텀 컴퓨터가 사용되는 순간 이를 막을 세상의 일반 컴퓨터의 보안은 와해되게 된다.)
1. 저렴한 병렬 컴퓨팅
2. 빅 데이타
3. 향상된 앨거리듬
신경망 (neural network)는 1950년대에 발명되었지만 수백만, 수 억 개의 뉴런들의 상호 연관성을 다루는 방법을 찾기까지 수십 년이 소요되었다. 얼굴인식을 예로 들자면, 눈 사진이 들어 오고 이 영상이 신경망에 한 패턴을 보일 때 이 결과는 다른 레벨로 옮겨져서 추가의 분석을 거치게 된다. 이 레벨에서는 눈 두 개를 묶어서 그 정보를 다음 레벨로 보낼 수 있다. 그 레벨에서는 이를 코와 묶어서 고려할 수 있다. 사람의 얼굴을 인식하려면 이런 노드 수백만개가 각각 주변의 다른 노드에 계산이 끝난 정보를 전달하는 것을 15 단계의 레벨에 걸쳐 처리해야 할지도 모른다.
2006년에 토론토대학교의 Geoff Hinton(제프 힌튼)은 이 방식에 한가지 매우 중요한 방법을 추가했는데 이를 딥 러닝 (deep learning 심화 학습) 이라고 부른다. 힌튼은 각 레벨에서 얻은 결과물을 수학적으로 최적화 (optimize) 시켰고, 이렇게 각 단계를 거쳐 올라가면서 학습이 빨리 되도록 만들었다.
이 방식의 딥 러닝 앨거리듬은 GPU (Graphics Processor Unit) 에 옮겨져 돌리게 되면서 엄청난 속도 개선이 되게 되었다. 딥 러닝 코드 자체만으로는 복잡한 논리적인 생각을 하는데 부족하지만 현재 IBM, 구글, 페이스북 등에서 사용하는 AI들은 모두 딥 러닝을 기본 핵심 방식으로 채택하고 있다.
[구인광고를 통한 요구사항 파악]
인텔 - experience with at least one of the following tools: Caffe, Torch, TensorFlow, Theano, or similar. Good understanding of CNNs, RNNs, reinforcement learning, supervised and unsupervised learning.
AMD
· Experience working with deep learning frameworks like Caffe, TensorFlow and Torch
· Strong mathematical foundation in Tensors, Convolutions, Linear Algebra, Numerical Mathematics, & Statistics
· Strong programming skills in C, C++, Perl, or Python
· Familiarity with GPU computing (CUDA, OpenCL) and HPC (MPI, OpenMP)
· Strong background in computer architecture
· Track record of optimizing code for performance on CPUs or GPUs, including assembly or SIMD programming
Amazon
· Hands on experience in building DNN, CNN, LSTM model and using commercial framework like TensorFlow/Caffe
Tesla
· data visualization
· SQL, R, and Python
· applied statistics including predictive modeling, Bayesian statistics, Time Series analysis and Machine Learning
· Java, Tableau, Hive, Spark, MongoDB
Panasonic
· deep-learning frameworks, such as Caffe, TensorFlow, Theano, Torch/PyTorch
· Python and C++, CUDA
기본적으로 Caffe, TensorFlow, Torch 등 세 가지를 언급하고 있다.
Caffe - http://caffe.berkeleyvision.org/ 버클리의 것이다. 만든사람인 Yangqing Jia 는 현재 페이스북에 있다. 그 전엔 구글에서 텐서플로우 작업도 했다. 페북은 지금 Caffe2 를 밀고 있다.
TensorFlow - 구글. ARM, ebay, Intel, Qualcomm, Kakao, Twitter, Uber, Dropbox, Airbnb, ...
Torch - NVIDIA 의 것. (테슬라가 사용하는지? 확인 필요.)
IBM과 애플, 아마존, 마이크로소프트등은 언급도 안된다.
Comparison of deep learning software - 차트로 잘 정리되어 있음.
[인공지능 적용분야]
- 비지니스 분석
- 번역, 통역
- 음성 인식
- 얼굴 인식
- 의료 영상 판독
- 유전학, 에너지, 환경, 기후 등에서 나오는 막대한 데이타 분석
- 질병 연구
- 게임 - 바둑, ... 데이타를 통한 학습 및 자가 학습. 자가학습의 예로는 블락 깨기가 있었음.
- 소프트웨어 테스팅
- 디지털 퍼스널 어시스턴트 - Siri, Alexa
- 고객 서비스 - Cogito
- 여행, 관광 - Boxever
- 판매 - 아마존 (언제 고객이 상품을 필요로 할 지 예측), 넷플릭스, 판도라,
- 실내 관리 - Nest (온도, ...)
- 기후 예측
- Vision, perception, control, planning algorithm development
[다음 할 일들]
1. 머신 러닝의 핵심 개념들
2. 머신 러닝 팩키지 해부